
CNN on the CIFAR-100 dataset, naive approaches
- 12 mins!nvidia-smi
Tue Dec 4 13:36:02 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.44 Driver Version: 396.44 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 36C P8 30W / 149W | 0MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
A Tesla K80 GPU is provided by Google on Google Colab, Keras uses the identified GPU by default so every machine learning algorithm is accelerated.
%pylab inline
Populating the interactive namespace from numpy and matplotlib
from keras.datasets import cifar100
(X_train, y_train), (X_test, y_test) = cifar100.load_data()
Using TensorFlow backend.
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
169009152/169001437 [==============================] - 56s 0us/step
X_train.shape, y_train.shape, X_test.shape, y_test.shape
((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1))
from keras.utils import to_categorical
to_categorical(y_train)[0, :].shape # number of categories
(100,)
X_train[0, :].shape # image shape
(32, 32, 3)
def visualize_random_images(images):
plt.figure(figsize=(6, 6))
for ind, img in enumerate(images[:9, :]):
plt.subplot(int("33%d" % (ind + 1)))
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
visualize_random_images(X_train)

from keras.models import Sequential
from keras.layers import MaxPooling2D, Conv2D, Flatten, Dense, Activation, Dropout
model = Sequential()
model.add(Conv2D(16, kernel_size=3, activation='relu'))
model.add(Conv2D(16, kernel_size=3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, kernel_size=3, activation='relu'))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(100, activation='softmax'))
from keras.utils import to_categorical
from keras.optimizers import Adam
from sklearn.preprocessing import normalize
from sklearn.preprocessing import OneHotEncoder
oh = OneHotEncoder(sparse=False)
oh.fit(y_train)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
history = model.fit(X_train/255., oh.transform(y_train), epochs=10, batch_size=32,
validation_data=(X_test/255., oh.transform(y_test)))
model.summary()
# list all data in history
print(history.history.keys())
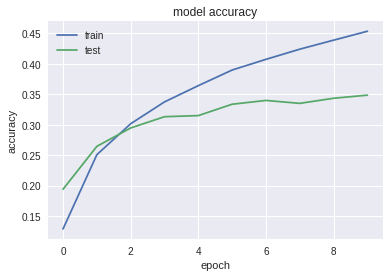
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
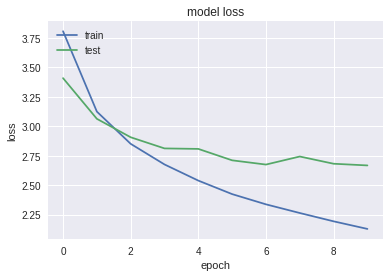
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
Train on 50000 samples, validate on 10000 samples
Epoch 1/10
50000/50000 [==============================] - 21s 411us/step - loss: 3.8072 - acc: 0.1288 - val_loss: 3.4091 - val_acc: 0.1940
Epoch 2/10
50000/50000 [==============================] - 16s 329us/step - loss: 3.1249 - acc: 0.2507 - val_loss: 3.0637 - val_acc: 0.2644
Epoch 3/10
50000/50000 [==============================] - 16s 329us/step - loss: 2.8513 - acc: 0.3015 - val_loss: 2.9071 - val_acc: 0.2946
Epoch 4/10
50000/50000 [==============================] - 16s 328us/step - loss: 2.6763 - acc: 0.3374 - val_loss: 2.8124 - val_acc: 0.3131
Epoch 5/10
50000/50000 [==============================] - 16s 327us/step - loss: 2.5391 - acc: 0.3641 - val_loss: 2.8082 - val_acc: 0.3149
Epoch 6/10
50000/50000 [==============================] - 16s 327us/step - loss: 2.4244 - acc: 0.3898 - val_loss: 2.7112 - val_acc: 0.3336
Epoch 7/10
50000/50000 [==============================] - 16s 326us/step - loss: 2.3376 - acc: 0.4073 - val_loss: 2.6753 - val_acc: 0.3398
Epoch 8/10
50000/50000 [==============================] - 16s 327us/step - loss: 2.2639 - acc: 0.4240 - val_loss: 2.7437 - val_acc: 0.3350
Epoch 9/10
50000/50000 [==============================] - 16s 325us/step - loss: 2.1933 - acc: 0.4388 - val_loss: 2.6823 - val_acc: 0.3434
Epoch 10/10
50000/50000 [==============================] - 16s 326us/step - loss: 2.1289 - acc: 0.4535 - val_loss: 2.6679 - val_acc: 0.3485
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 30, 30, 16) 448
_________________________________________________________________
conv2d_2 (Conv2D) (None, 28, 28, 16) 2320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 12, 12, 32) 4640
_________________________________________________________________
conv2d_4 (Conv2D) (None, 10, 10, 32) 9248
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 800) 0
_________________________________________________________________
dense_1 (Dense) (None, 100) 80100
=================================================================
Total params: 96,756
Trainable params: 96,756
Non-trainable params: 0
_________________________________________________________________
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
from keras.optimizers import SGD
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=(X_train.shape[1:])))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(100))
model.add(Activation('softmax'))
# let's train the model using SGD + momentum (how original).
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 30, 30, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 30, 30, 32) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 15, 15, 64) 18496
_________________________________________________________________
activation_3 (Activation) (None, 15, 15, 64) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 13, 13, 64) 36928
_________________________________________________________________
activation_4 (Activation) (None, 13, 13, 64) 0
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 6, 6, 64) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 1180160
_________________________________________________________________
activation_5 (Activation) (None, 512) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 100) 51300
_________________________________________________________________
activation_6 (Activation) (None, 100) 0
=================================================================
Total params: 1,297,028
Trainable params: 1,297,028
Non-trainable params: 0
_________________________________________________________________
history = model.fit(X_train/255., to_categorical(y_train), epochs=25, batch_size=32,
validation_data=(X_test/255., to_categorical(y_test)))
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
Train on 50000 samples, validate on 10000 samples
Epoch 1/25
50000/50000 [==============================] - 22s 444us/step - loss: 2.8531 - acc: 0.2877 - val_loss: 2.6908 - val_acc: 0.3254
Epoch 2/25
50000/50000 [==============================] - 22s 442us/step - loss: 2.7651 - acc: 0.3027 - val_loss: 2.5859 - val_acc: 0.3600
Epoch 3/25
50000/50000 [==============================] - 22s 443us/step - loss: 2.6833 - acc: 0.3198 - val_loss: 2.6359 - val_acc: 0.3502
Epoch 4/25
50000/50000 [==============================] - 22s 445us/step - loss: 2.6107 - acc: 0.3364 - val_loss: 2.4280 - val_acc: 0.3784
Epoch 5/25
50000/50000 [==============================] - 22s 443us/step - loss: 2.5424 - acc: 0.3515 - val_loss: 2.4913 - val_acc: 0.3745
Epoch 6/25
50000/50000 [==============================] - 22s 442us/step - loss: 2.4920 - acc: 0.3580 - val_loss: 2.4161 - val_acc: 0.3820
Epoch 7/25
50000/50000 [==============================] - 22s 442us/step - loss: 2.4510 - acc: 0.3669 - val_loss: 2.4224 - val_acc: 0.3816
Epoch 8/25
50000/50000 [==============================] - 22s 442us/step - loss: 2.4155 - acc: 0.3755 - val_loss: 2.3747 - val_acc: 0.3954
Epoch 9/25
50000/50000 [==============================] - 22s 442us/step - loss: 2.3885 - acc: 0.3825 - val_loss: 2.4870 - val_acc: 0.3711
Epoch 10/25
50000/50000 [==============================] - 22s 441us/step - loss: 2.3507 - acc: 0.3876 - val_loss: 2.4197 - val_acc: 0.3798
Epoch 11/25
50000/50000 [==============================] - 22s 442us/step - loss: 2.3255 - acc: 0.3944 - val_loss: 2.3799 - val_acc: 0.3905
Epoch 12/25
50000/50000 [==============================] - 22s 439us/step - loss: 2.2929 - acc: 0.4002 - val_loss: 2.3137 - val_acc: 0.4021
Epoch 13/25
50000/50000 [==============================] - 22s 439us/step - loss: 2.2695 - acc: 0.4033 - val_loss: 2.3239 - val_acc: 0.4025
Epoch 14/25
50000/50000 [==============================] - 22s 438us/step - loss: 2.2655 - acc: 0.4075 - val_loss: 2.3089 - val_acc: 0.4175
Epoch 15/25
50000/50000 [==============================] - 22s 440us/step - loss: 2.2432 - acc: 0.4118 - val_loss: 2.3701 - val_acc: 0.3916
Epoch 16/25
50000/50000 [==============================] - 22s 439us/step - loss: 2.2297 - acc: 0.4134 - val_loss: 2.3135 - val_acc: 0.4107
Epoch 17/25
50000/50000 [==============================] - 22s 437us/step - loss: 2.1917 - acc: 0.4206 - val_loss: 2.3532 - val_acc: 0.4041
Epoch 18/25
50000/50000 [==============================] - 22s 438us/step - loss: 2.2088 - acc: 0.4209 - val_loss: 2.3615 - val_acc: 0.3984
Epoch 19/25
50000/50000 [==============================] - 22s 438us/step - loss: 2.1794 - acc: 0.4239 - val_loss: 2.3723 - val_acc: 0.4009
Epoch 20/25
50000/50000 [==============================] - 22s 442us/step - loss: 2.1681 - acc: 0.4268 - val_loss: 2.3420 - val_acc: 0.4068
Epoch 21/25
50000/50000 [==============================] - 22s 441us/step - loss: 2.1660 - acc: 0.4298 - val_loss: 2.3142 - val_acc: 0.4081
Epoch 22/25
50000/50000 [==============================] - 22s 440us/step - loss: 2.1480 - acc: 0.4327 - val_loss: 2.3624 - val_acc: 0.3983
Epoch 23/25
50000/50000 [==============================] - 22s 441us/step - loss: 2.1400 - acc: 0.4352 - val_loss: 2.3972 - val_acc: 0.3897
Epoch 24/25
50000/50000 [==============================] - 22s 440us/step - loss: 2.1488 - acc: 0.4324 - val_loss: 2.3606 - val_acc: 0.4033
Epoch 25/25
50000/50000 [==============================] - 22s 441us/step - loss: 2.1233 - acc: 0.4392 - val_loss: 2.3853 - val_acc: 0.3985
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
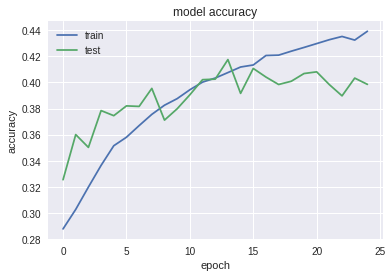
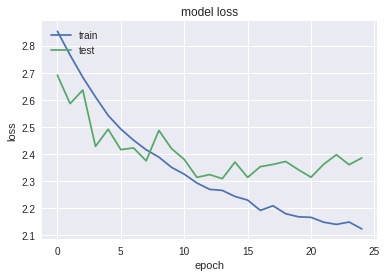
It can be clearly seen that the model overfitted the data since the training set constantly eliminates loss while the test set is nearly constant after the 15th epoch and evan getting higher.
@Regards, Alex

Alex Olar
Christian, foodie, physicist, tech enthusiast