
Photometric redshift estimation 3.
- 18 minsTemplate set generation from theoratical
In this section I am generating template sets with different redshifts from theoretical galaxy spectra. The method is the following. We are assuming a galaxy spectra from different types of theories and each of them is imported into my project. After that I use the filters acquired from László Dobos. With these filters I calculate the flux with the following integral:
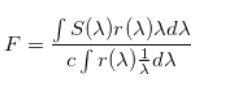
Where c is the speed of light and r($\lambda$) is the filter finction while S($\lambda$) is the spectral function of the appropiate galaxy. From the following equation the AB magnitude can be generated as follows:
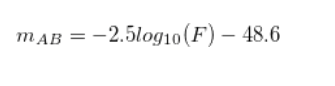
For the integrals I used the following numerical method. I didn’t rebin the data but I first looked for the minimum and maximum index of the nearest wavelength from the filters end in the spectral distribution. When I found this, I ran through that part of the spectral function and always multiplied the appropiate spectral value with the nearest filter function value according to wavelength. With this method I approximated the integrals and took into account that the wavelengths are in angström.
Acquired data
I downloaded the filters from here and used these. The template data is acquired from the Le Phare template set downloaded from here. The created data is stored and reread by another notebook that uses a measured set and finds the best fitting template values.
The template values are generated by multiplying the wavelengths with (1+z) where z in [0,1]. I used N steps to raise z from 0 to 1 and update the wavelengths, calculating the magnitues and building the dataframe.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from os import listdir
import re
# Not used galaxy spectra from László Dobos
files = listdir(path='./kompozit_dobos_data/data/')
files = np.array(list(filter(lambda x: re.match(r'.*\.spec\..', x), files)))
files.flatten(), files.size
(array(['s_GG.spec.txt', 'l_GG.spec.txt', 'SF4_0.spec.txt',
'RED2_0.spec.txt', 'p_G.spec.txt', 'SF1_0.spec.txt',
'l_RG.spec.txt', 'l_G.spec.txt', 'h_G.spec.txt', 'BG.spec.txt',
'l_BG.spec.txt', 'p_BG.spec.txt', 'h_GG.spec.txt',
'SF0_0.spec.txt', 'RED4_0.spec.txt', 's_G.spec.txt',
'SF2_0.spec.txt', 'hh_RG.spec.txt', 't_GG.spec.txt',
'p_GG.spec.txt', 'G.spec.txt', 'SF3_0.spec.txt', 'hh_G.spec.txt',
't_BG.spec.txt', 'h_RG.spec.txt', 's_RG.spec.txt',
'RED1_0.spec.txt', 's_BG.spec.txt', 'hh_GG.spec.txt',
'p_RG.spec.txt', 't_RG.spec.txt', 'hh_BG.spec.txt',
'RED0_0.spec.txt', 'h_BG.spec.txt', 'GG.spec.txt', 'RG.spec.txt',
'RED3_0.spec.txt', 't_G.spec.txt'], dtype='<U15'), 38)
# Reading the files into arrays
def get_spectra_dobos(files):
spectra = []
for file in files:
# Reading text files with Pandas
data = pd.read_csv('kompozit_dobos_data/data/%s' % file, sep="\t", header=None)
# Converting from scientific notation
data = data.apply(pd.to_numeric, args=('coerce',))
# Using the wavelength and the flux only
spectra.append(data.values[1:,0:2])
return np.array(spectra)
spectra_dobos = get_spectra_dobos(files)
# Plotting all in one
plt.figure(figsize=(15.,9.))
plt.xlabel('Wavelength [Angstrom]')
plt.ylabel('Flux []')
plt.title('Galaxy spectra')
# Filter spectrum
plt.xlim(3000,9500)
for i in range(len(spectra_dobos)):
plt.plot(spectra_dobos[i][:,0][::100], spectra_dobos[i][:,1][::100])
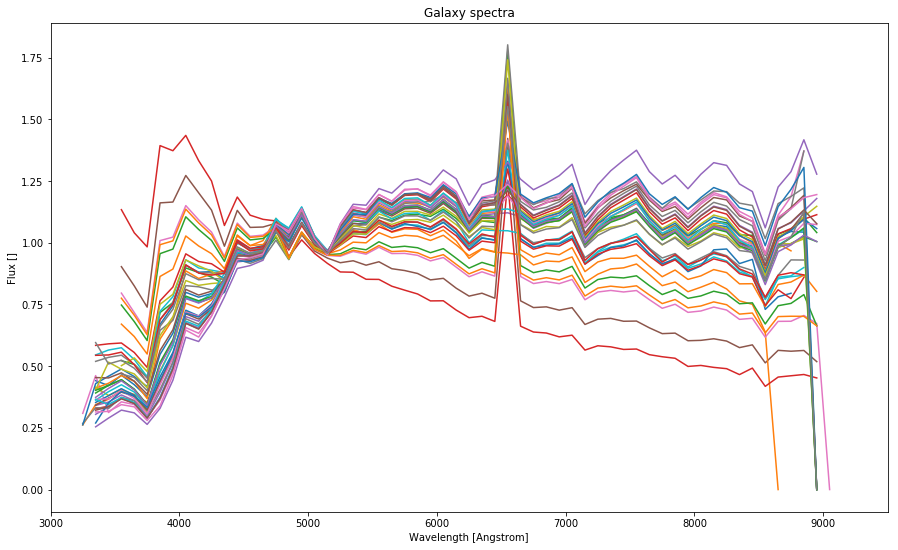
It will become evident later that these spectral functions cannot be used without modification since the do not cover the whole spectrum and thus they cannot be just evidently multiplied with the filters.
def get_lephare_spectra():
# Reading the Le Phare sepctra
dirs = listdir(path='lephare_dev/sed/GAL/')
files = np.array([])
spectra = []
filenames = []
for dr in dirs:
# Some kind of bug, dirs read with ._ at the beginning
if(dr[0] != "."):
files = listdir(path='lephare_dev/sed/GAL/%s/' % dr)
file_names = np.array(list(filter(lambda x: re.match(r'.*\.sed', x), files)))
for file in file_names:
# Some kind of bug, dirs read with ._ at the beginning
if(file[0] != "."):
# Due to erros in file formatting
try:
# Reading in %.3f format
pd.set_option('display.float_format', lambda x: '%.3f' % x)
# Read with any whitespace separator (still some errors)
data = pd.read_csv('lephare_dev/sed/GAL/%s/%s' % (dr, file), sep=r"\s*",
header=None, engine='python')
# Numeric
data = data.apply(pd.to_numeric, args=('coerce',))
data = data.dropna(axis='rows')
if(len(data.values.shape) > 1 and data.values.shape[0] != 0 and data.values.shape[1] != 0):
filenames.append('lephare_dev/sed/GAL/%s/%s' % (dr, file))
spectra.append(data.values[:, 0:2])
finally:
# Progress bar
print('=', end='')
# End progress bar
print(">\t", len(spectra))
return np.array(spectra), np.array(filenames)
Reading the Le Phare spectra still produces some error logs due to the mismatch in the data files.
lephare_spectra, filenames = get_lephare_spectra()
/home/alex.olar@odigeo.org/anaconda3/lib/python3.6/site-packages/pandas/io/parsers.py:2230: FutureWarning: split() requires a non-empty pattern match.
yield pat.split(line.strip())
/home/alex.olar@odigeo.org/anaconda3/lib/python3.6/site-packages/pandas/io/parsers.py:2232: FutureWarning: split() requires a non-empty pattern match.
yield pat.split(line.strip())
===========================================================================================================================================================================================================================================================================================================> 299
i = 1
plt.figure(figsize=(24, 32))
for j in range(4, lephara_spectra.size, 33):
plt.subplot(int('43%d' % i))
i += 1
plt.xlim(2900,13000)
plt.title('Data from: %s' % filenames[j])
plt.xlabel('Wavelength [Angstrom]')
plt.ylabel('Flux []')
plt.plot(lephare_spectra[j][:,0], lephare_spectra[j][:,1])
plt.show()
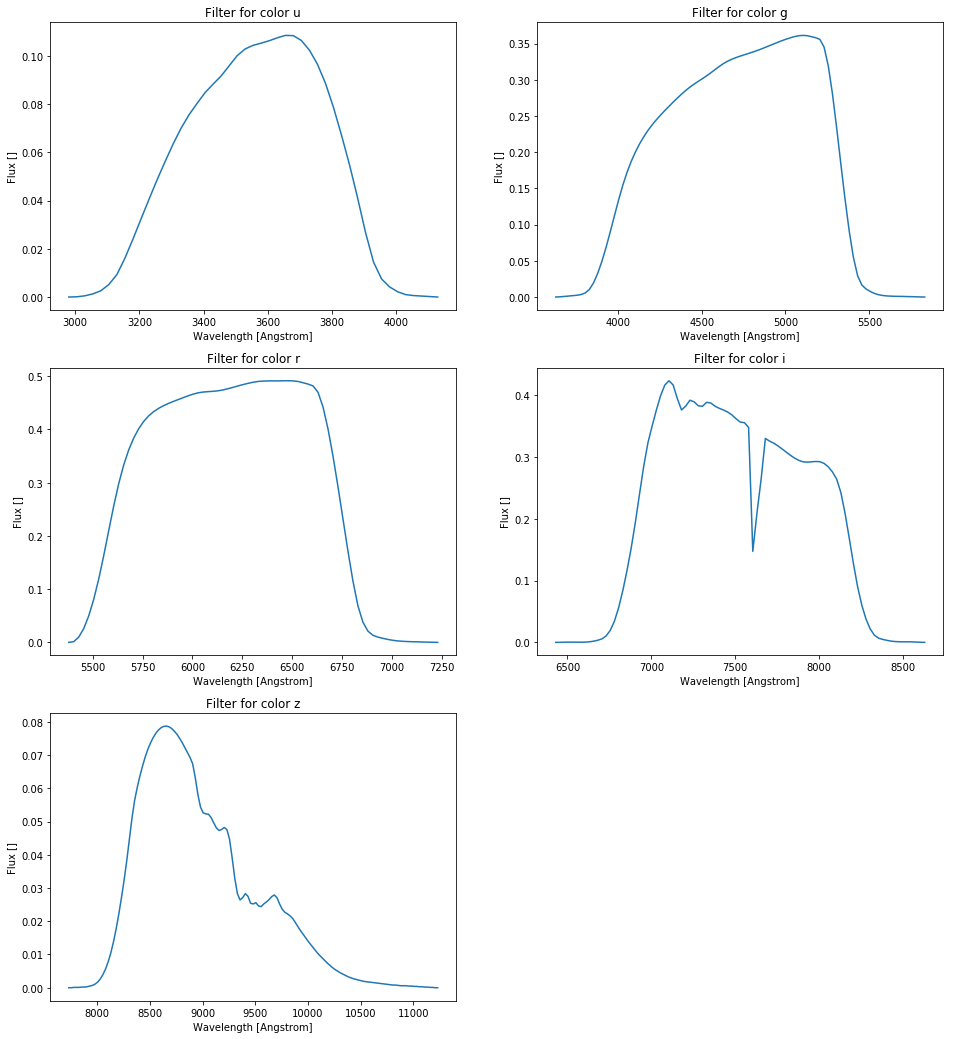
colors = ['u', 'g', 'r', 'i', 'z']
filters = np.array([pd.read_csv('./SDSS_%s\'.txt' % c, sep=r"\s", header=None, engine='python').values for c in colors])
plt.figure(figsize=(16.,18.))
for ind, color in enumerate(colors):
plt.subplot(int("32%d" % (ind+1)))
plt.title('Filter for color %s' % color)
plt.xlabel("Wavelength [Angstrom]")
plt.ylabel("Flux []")
plt.plot(filters[ind][:,0], filters[ind][:,1])
plt.show()
Here is the above mentioned magnitude calculating function
def get_spectrum(spectrum, color_filter):
# min/max wavelength
min_lambda = color_filter[:,0][0]
max_lambda = color_filter[:,0][-1]
# find nearest min/max indices
min_nearest_ind = np.abs(spectrum[:,0]-min_lambda).argmin()
max_nearest_ind = np.abs(spectrum[:,0]-max_lambda).argmin()
# integral of response function
c = 3*10**8
bin_width = color_filter[:,0][1] - color_filter[:,0][0]
filter_integral = c*np.sum(color_filter[:,1]/color_filter[:,0])*10**10 # dimension correction
flux = 0.
for ind, val in enumerate(spectrum[:,0][min_nearest_ind:max_nearest_ind]):
nearest_ind = np.abs(color_filter[:,0] - val).argmin()
flux += color_filter[:, 1][nearest_ind]*spectrum[:,1][ind]*val*10**(-10) # dimension correction
return -2.5*np.log10(flux/filter_integral) - 48.60
By default 50 steps.
def build_dataframe_from_template(_spectra, _colors, _N=50):
data = []
spectra = _spectra.copy()
colors = np.append(_colors, ['redshift'])
for z in np.linspace(0.,1.,_N):
for j in range(spectra.size):
row = []
spectrum = spectra[j].copy()
spectrum[:,1] *= (1.+z)
for i in range(filters.size):
# magnitudes and redshift
row.append(get_spectrum(spectrum, filters[i]))
row.append(z)
data.append(row)
# Building dataframe \w column names
return pd.DataFrame(data, columns=colors)
template_data = build_dataframe_from_template(lephara_spectra, colors, 10)
template_data
| u | g | r | i | z | redshift | |
|---|---|---|---|---|---|---|
| 0 | 8.044 | 6.575 | 6.266 | 5.603 | 5.202 | 0.000 |
| 1 | 8.066 | 6.798 | 6.284 | 5.789 | 5.436 | 0.000 |
| 2 | 5.892 | 3.422 | 3.275 | 2.508 | 2.083 | 0.000 |
| 3 | 7.570 | 5.641 | 5.403 | 4.704 | 4.294 | 0.000 |
| 4 | 8.003 | 6.709 | 6.219 | 5.705 | 5.347 | 0.000 |
| 5 | 6.087 | 4.029 | 3.937 | 3.110 | 2.671 | 0.000 |
| 6 | 7.818 | 6.081 | 5.774 | 5.127 | 4.730 | 0.000 |
| 7 | 7.935 | 6.665 | 6.154 | 5.656 | 5.304 | 0.000 |
| 8 | 5.802 | 3.484 | 3.362 | 2.573 | 2.144 | 0.000 |
| 9 | 5.821 | 3.746 | 3.661 | 2.828 | 2.389 | 0.000 |
| 10 | 4.926 | 1.743 | 1.480 | 0.817 | 0.443 | 0.000 |
| 11 | 7.646 | 4.340 | 4.140 | 3.418 | 3.015 | 0.000 |
| 12 | 7.878 | 4.562 | 4.366 | 3.639 | 3.234 | 0.000 |
| 13 | 8.292 | 4.952 | 4.769 | 4.030 | 3.618 | 0.000 |
| 14 | 6.593 | 3.328 | 3.107 | 2.405 | 2.017 | 0.000 |
| 15 | 7.579 | 4.275 | 4.073 | 3.353 | 2.951 | 0.000 |
| 16 | 7.795 | 4.483 | 4.285 | 3.560 | 3.156 | 0.000 |
| 17 | 4.760 | 1.587 | 1.319 | 0.661 | 0.287 | 0.000 |
| 18 | 8.579 | 5.216 | 5.044 | 4.295 | 3.876 | 0.000 |
| 19 | 8.173 | 4.840 | 4.653 | 3.918 | 3.508 | 0.000 |
| 20 | 7.718 | 4.409 | 4.210 | 3.487 | 3.083 | 0.000 |
| 21 | 4.840 | 1.662 | 1.396 | 0.736 | 0.362 | 0.000 |
| 22 | 3.669 | 0.628 | 0.320 | -0.302 | -0.668 | 0.000 |
| 23 | 9.237 | 5.796 | 5.661 | 4.876 | 4.438 | 0.000 |
| 24 | 4.110 | 1.019 | 0.725 | 0.090 | -0.279 | 0.000 |
| 25 | 10.116 | 6.487 | 6.437 | 5.569 | 5.089 | 0.000 |
| 26 | 4.686 | 1.517 | 1.247 | 0.591 | 0.217 | 0.000 |
| 27 | 5.233 | 2.029 | 1.777 | 1.104 | 0.728 | 0.000 |
| 28 | 3.867 | 0.806 | 0.504 | -0.123 | -0.491 | 0.000 |
| 29 | 8.426 | 5.076 | 4.898 | 4.154 | 3.739 | 0.000 |
| ... | ... | ... | ... | ... | ... | ... |
2990 rows × 6 columns
After saving the template data and storing it in CSV format, we will need to read and match it with real world data and after that run through the Beck method again.
template_data = pd.read_csv('template_dataset_150_steps_from0to1_approx45000lines.csv')
template_data.head(n=3)
| Unnamed: 0 | u | g | r | i | z | redshift | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 8.044391 | 6.575220 | 6.266480 | 5.602644 | 5.201868 | 0.0 |
| 1 | 1 | 8.065978 | 6.797687 | 6.284164 | 5.788807 | 5.435865 | 0.0 |
| 2 | 2 | 5.892363 | 3.422409 | 3.274510 | 2.507776 | 2.082993 | 0.0 |
measured_data = pd.read_csv('SDSSDR7-5-percent-err-limit-250000-line.csv')
measured_data['redshift'] = measured_data['z'] # rename column z to redshift (name mismatch)
measured_data['r'] = measured_data['m_r']
measured_data.head(n=3)
| m_u | m_g | m_r | m_i | m_z | pm_u | pm_g | pm_r | pm_i | pm_z | ... | gr | ri | iz | p_ug | p_gr | p_ri | p_iz | z | redshift | r | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.72349 | 16.81077 | 15.82313 | 15.38485 | 15.10698 | 18.84772 | 16.89205 | 15.93285 | 15.48446 | 15.26974 | ... | 0.939638 | 0.407642 | 0.249907 | 1.892926 | 0.911196 | 0.417752 | 0.186763 | 0.073380 | 0.073380 | 15.82313 |
| 1 | 19.95914 | 18.37869 | 17.28570 | 16.84375 | 16.51609 | 20.35225 | 18.61696 | 17.53188 | 17.05937 | 16.80484 | ... | 1.041871 | 0.409317 | 0.297886 | 1.668472 | 1.033958 | 0.439880 | 0.224745 | 0.188367 | 0.188367 | 17.28570 |
| 2 | 20.94537 | 18.69572 | 17.47588 | 16.93906 | 16.55628 | 20.80478 | 18.68200 | 17.49543 | 16.96157 | 16.60848 | ... | 1.174170 | 0.507675 | 0.356186 | 2.063087 | 1.140913 | 0.504709 | 0.326489 | 0.156023 | 0.156023 | 17.47588 |
3 rows × 26 columns
In order to be able to use later on de column names for the Beck-method
template_data['ug'] = template_data['u'] - template_data['g']
template_data['gr'] = template_data['g'] - template_data['r']
template_data['ri'] = template_data['r'] - template_data['i']
template_data['iz'] = template_data['i'] - template_data['z']
template_data.head(n=3)
| Unnamed: 0 | u | g | r | i | z | redshift | ug | gr | ri | iz | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 8.044391 | 6.575220 | 6.266480 | 5.602644 | 5.201868 | 0.0 | 1.469171 | 0.308739 | 0.663837 | 0.400776 |
| 1 | 1 | 8.065978 | 6.797687 | 6.284164 | 5.788807 | 5.435865 | 0.0 | 1.268291 | 0.513523 | 0.495357 | 0.352942 |
| 2 | 2 | 5.892363 | 3.422409 | 3.274510 | 2.507776 | 2.082993 | 0.0 | 2.469954 | 0.147899 | 0.766734 | 0.424782 |
Representation of the function that will do the template selection based on real world, measured data.
def find_nearest_template_in_measured_data(template_data, measured_data, indices):
for row in measured_data[indices].values:
print('MEASURED DATA:\t', row)
min_ind = np.argmin([np.sqrt(np.sum(np.square(row - val))) for val in template_data[indices].values])
print('BEST TEMPLATE DATA: ',template_data[indices].values[min_ind, :], ' - MIN INDEX :', min_ind)
break
find_nearest_template_in_measured_data(template_data, measured_data, ['ug', 'gr', 'ri', 'iz', 'redshift' ])
MEASURED DATA: [1.849979 0.9396375 0.4076419 0.2499068 0.0733804]
BEST TEMPLATE DATA: [1.73692124 0.30741608 0.6469574 0.39612702 0.0738255 ] - MIN INDEX : 3295
Mathing done batching the measured data and finding the nearest match in the template set. The output is N dataframes that are saved in CSV and the stored columns are ‘ug’, ‘gr’, ‘ri’, ‘iz’, and the ‘redshift’.
def find_nearest_template_in_measured_data(template_data, measured_data, indices, batch=100):
splitted_datasets = np.split(measured_data[indices].values, batch)
dataframes = []
for num, dataset in enumerate(splitted_datasets):
pd.set_eng_float_format(accuracy=5, use_eng_prefix=True)
best_template_data = []
for row in dataset:
min_ind = np.argmin(np.linalg.norm(template_data[indices].values - row, axis=1))
best_template_data.append(template_data[indices].values[min_ind, :])
dataframe = pd.DataFrame(data=np.array(best_template_data), columns=indices)
dataframe.to_csv('dataframes/dataframe%d.csv' % num)
return
find_nearest_template_in_measured_data(template_data, measured_data, ['r', 'ug', 'gr', 'ri', 'iz', 'redshift' ])
This created 100 dataframes that will need to be concatenated and fed into Beck’s method.
@Regards, Alex

Alex Olar
Christian, foodie, physicist, tech enthusiast