Training RoBERTa and Reformer with Huggingface
- 9 minsTraining language models from scratch
This a post after more than a month of silence, however, I was busy reading, working and did not have time to allocate for blogging. I’ve started reading Information Theory from MacKay and Probability Theory from Jaynes which are both fascinating reads and are extremely intriguing while I was also focusing on research ideas (hence the blog post). I hope to write about information theory sometime soon, I also read some papers about it recently such as BB-ANS or other lossless image compression algorithms.
Currently, I am experimenting with transformer models but not for language modeling. A recent paper just improved the attention mechanism of the transformer while mathematically justifying that in the limit they get back the same attention matrix but in much less computation. This one was called Performer but today I am not writing about that since it is only implemented efficiently in JAX so far and can’t yet be practically used, as far as I know. Its direct predecessor is the Reformer which also approximates sufficiently well the attention matrix with the LSH (locality sensitive hashing) but is less computationally heavy.
Why is this important?
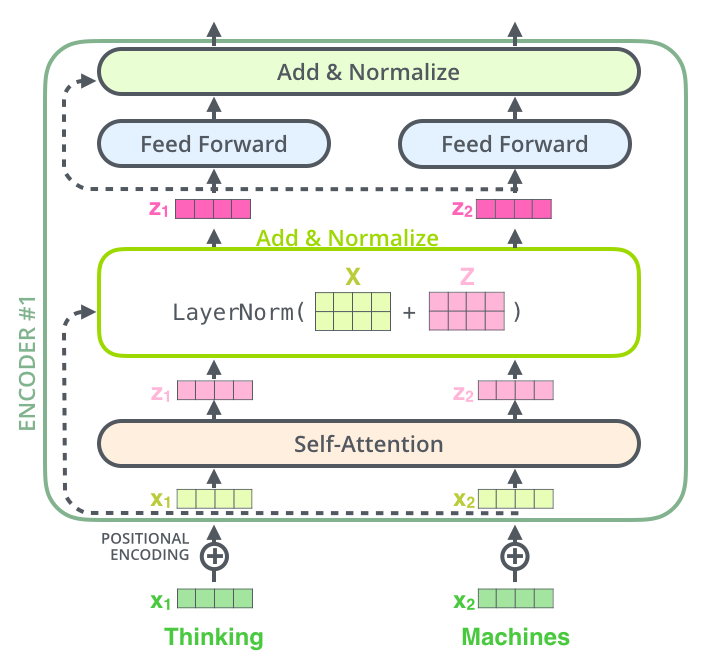
A BERT model can feasibly handle 512 length tokens as sequences at a time (a batch of it to be more specific). Since the attention mechanism originally requires O(n^2) in memory and computational time there were many attempts to approximate this to be able to handle much longer sequences: Longformer, Linformer, etc. Reformer is such an architecture that approximates the attention matrix by separating the embedded queries into hash buckets based on random vectors and only calculating attention scores in buckets. This saves a lot of computation and they also apply a lot of tricks to achieve amazing results. Read this blog post on the Huggingface blog if you are interested in the details. The Reformer can handle sequences up to ~4000 tokens long with less than 10GB of GPU RAM on a basic gaming system, the Performer can even do better which is truly jaw-dropping. It seems that finally, it is true: attention is all you need, and at last, you can also have it. :) I don’t want to speculate here but my hopes are high that transformer-based models are finally efficient enough for the general public of researchers and not just large tech companies with tens-of-thousands of TPU hours to spare (~100,000$).
Technicalities
Intro
It seems to me that ![]() Transformers are THE framework to use for NLP with deep-learning. As I see now the framework used to be a configurable collection of pre-defined scripts but currently, it is being developed towards becoming a general-purpose framework for NLP. It features a ridiculous amount of models ranging from all BERT, GPT flavors to more recent ones such as Reformer.
Transformers are THE framework to use for NLP with deep-learning. As I see now the framework used to be a configurable collection of pre-defined scripts but currently, it is being developed towards becoming a general-purpose framework for NLP. It features a ridiculous amount of models ranging from all BERT, GPT flavors to more recent ones such as Reformer.
RoBERTa
The Huggingface blog features training RoBERTa for the made-up language Esperanto. They download a large corpus (a line-by-line text) of Esperanto and preload it to train a tokenizer and a RoBERTa model from scratch.
Tokenization
Firstly the data needs to be downloaded:
$ wget -c https://cdn-datasets.huggingface.co/EsperBERTo/data/oscar.eo.txt
$ head -n2 oscar.eo.txt
Ĉu ... preĝi | mediti | ricevi instigojn || kanti | muziki || informiĝi | legi | studi || prepari Diservon
Temas pri kolekto de kristanaj kantoj, eldonita de Adolf Burkhardt inter 1974 kaj 1990 en dek kajeretoj. Ili estas reeldonitaj inter 1995 kaj 1998 de Bernhard Eichkorn en tri kajeroj, kies tria estas pliampleksigita per Dek Novaj Kantoj kaj suplemento, same de Adolf Burkhardt.
En la dua kaj tria kajero oni adiciis 300 al la originaj kantonumeroj, por ke oni povu pli facile uzi la kajerojn kune kun la KELI-himnaro Adoru Kantante, kiu havas malpli ol 300 numerojn.
The tokenization is based on the byte part encoding (BPE) algorithm that basically merges/clusters often occurring byte-parts to form a token in the vocabulary for training a language model.
from tokenizers import ByteLevelBPETokenizer
paths = [str(Path("oscar.eo.txt"))]
tokenizer = ByteLevelBPETokenizer()
tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
tokenizer.save_model(".")
The training of the tokenizer features this merging process and finally, a vocabulary of 52_000 tokens is formed at the end of the process. Special tokens are added to the vocabulary representing the start and end of the input sequence (<s>, </s>) and also unknown, mask and padding tokens are added - the first is needed for unknown sub-strings during inference, masking is required for language modeling since the training is based on masking out a random number of the input tokens in the sequence and predicting those correctly, padding is needed for short sentences since batched training requires uniform length input.
Language modeling
A common language modeling task is to randomly mask some of the input sequences (~15%) and try to predict those masked out parts of the sentence. We will use RoBERTa, an optimized BERT flavor that is used for bidirectional, masked language modeling, and finally for downstream tasks.
from transformers import RobertaConfig
config = RobertaConfig(
vocab_size=52_000,
max_position_embeddings=514,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1,
)
The maximum positional embedding size here is the maximum length we wish to provide as the input sequence length (512) + 2 tokens representing the start and the end of the sequence. Here we also configure the size of the model, such as the number of attention heads in each layer, the number of layers, etc.
We are loading the pre-trained tokenizer into the model-specific tokenizer which features other post-processing steps (such as adding <s>, </s> for example) and adds padding if necessary:
from transformers import RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("./EsperBERTo", max_len=512)
Now we are ready to set up the model. In Huggingface we have different setups of RoBERTa transformers for different tasks, such as masked language modeling, casual language modeling, etc. Here we set up masked language modeling and finally we prepared the model:
from transformers import RobertaForMaskedLM
model = RobertaForMaskedLM(config=config)
Data preparation
As the model is properly configured and set up we load the text line-by-line with a predefined dataset loader:
from transformers import LineByLineTextDataset
dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path="./oscar.eo.txt",
block_size=128)
Huggingface uses a so-called DataCollator which handles the batches for the specific task. When we want our model to predict masked out parts the batch is not fed into directly to the model but the task-specific DataCollator to prepare it.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
Finally, the model can be trained!
Model training
If you have ever used PytorchLightning before the Trainer should be familiar. Huggingface adds a training arguments class that configures the Trainer:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=1,
per_gpu_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
prediction_loss_only=True,
)
trainer.train()
Basically, that’s it. Afterward, you have a properly setup training pipeline with a RoBERTa model. Huggingface provides integration with Weights & Biases which logs every metric and compute usage while training online. You have to have a W&B account and pip install the wandb package but having set up everything you just need to log in at that’s it with Huggingface, neat!
But how to do this with Reformer?
As of right now, I found a bug in the Reformer implementation since it does not work properly for casual language modeling, only for masked language modeling. For the Reformer model, you need to train a different type of tokenizer, called sentence piece. The sentence piece tokenizer is what its name suggests, tokenizes to pieces of sentences. To train the sentence piece tokenizer on your own dataset you need to:
import sentencepiece as spm
args = "--input=./oscar.eo.txt --model_prefix=ESPERANTO --vocab_size=325 --max_sentence_length=500"
spm.SentencePieceTrainer.train(args)
Here I required the line length to be less than 500 characters and the vocabulary has been set to 325 characters as an upper bound. The algorithm set it to 273. This type of tokenizer could be great for a low vocabulary size sequencing task. The training takes some time, but in the end, you should get an ESPERANTO.model and an ESPERANTO.vocab file. The vocab file is in plain-text, while the model file is that one that should be loaded for the ReformerTokenizer in Huggingface. Moving on, the steps are fundamentally the same as before for masked language modeling, and as I mentioned for casual language modeling currently (2020. 11. 13.) there is a bug with the Reformer model.
Outlook
It was just recently that this paper gained popularity, claiming that you could do SOTA ImageNet classification with transformers only. They used a trick to be able to handle images from the dataset but currently, it seems that this bottleneck is eliminated and we could finally train image recognition models via transformer architectures, also it is already possible to do so for object detection. These approaches used an obscene amount of computation before but let’s hope that the future is much more efficient.
@Regards, Alex

Alex Olar
Christian, foodie, physicist, tech enthusiast