SimCLR - simple contrastive learning
- 5 minsContrastive learning
Recently some really great papers came out regarding unsupervised pre-training/unsupervised feature learning. To mention the most prominent ones MoCoV1/V2 use momentum contrast between two encoder neural networks and also uses either a large buffer and/or very large batch sizes applying the contrastive loss. Some methods do not even use contrastive losses, such as BYOL, SWaV. The surge of papers shows that unsupervised and weakly-supervised traning are very lively topics currently and they are very promising for applications.
Contrastive learning
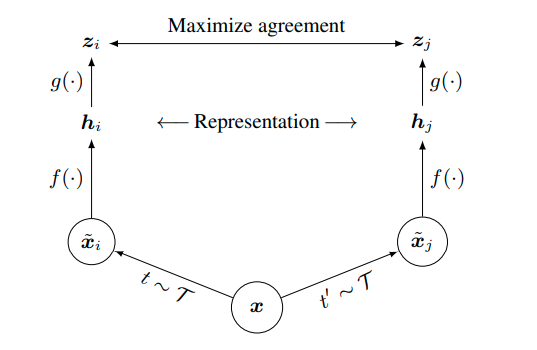
Contrastive learning basically takes the idea that two randomly transformed images should be similar despite the heavy modifications. This can be achieved by simple applying different stochastic transformations for the same batch of images and requiring that different embeddings of transformed images should be similar whilst similar transforms of different images should differ in embedding space.
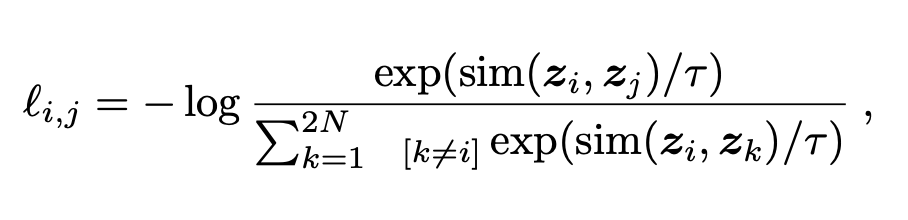
Where \(z_i\) and \(z_j\) are different embeddings of the same image while it is normalized by the different image embeddings. The \(\tau\) parameter is the temperature for the negative log-likelihood that helps during training.
SimCLR
What SimCLR does? Lot of compute, lower dimensional projection of the embedding space to do contrastive learning on whilst acquiring great embeddings.
Here is also an image:

Basically, that is it. It is extremely simple but needs a lot of compute to work well. The batch sizes should be as large as possible in order to work well.
Naive implementation
I went on and tried to implement it in PyTorch. I used the CIFAR10 dataset and applied some random transformations on it.
cifar10_unsup = torchvision.datasets.CIFAR10(
root='./data/',
download=True,
train=True,
transform=T.Compose([
T.RandomApply(
[T.ColorJitter(brightness=.9, contrast=.6, saturation=0.4)],
p=0.5),
T.RandomResizedCrop(size=(32, 32)),
T.RandomVerticalFlip(),
T.RandomGrayscale(),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]))
The SimCLR architecture itself is almost ridiculouosly simple:
class SimCLR(torch.nn.Module):
def __init__(self):
super(SimCLR, self).__init__()
resnet = torchvision.models.resnet50(pretrained=True)
n_features = resnet.fc.in_features
features = list(resnet.children())[:-1]
self.features = torch.nn.Sequential(*features)
self.mlp = torch.nn.Sequential(*[
torch.nn.Linear(n_features, n_features),
torch.nn.ReLU(),
torch.nn.Linear(n_features, 256)
])
def forward(self, inputs):
features = self.features(inputs)
features = features.squeeze()
embeddings = self.mlp(features)
return embeddings, features
The contrastive loss is a bit trickier, I went on and attempted to implement it myself but later on I found the PyTorch Lightning Bolts implementation after which I realized that I could not surpass their simplicity. This type of contrastive loss is called NT Xent loss:
def nt_xent_loss(out1, out2, temperature, device):
out = torch.cat([out1, out2], dim=0)
n_samples = len(out)
# Full similarity matrix
cov = torch.mm(out, out.t().contiguous())
sim = torch.exp(cov / temperature)
# Negative similarity
mask = ~torch.eye(n_samples, device=device).bool()
neg = sim.masked_select(mask).view(n_samples, -1).sum(dim=-1)
# Positive similarity :
pos = torch.exp(torch.sum(out1 * out2, dim=-1) / temperature)
pos = torch.cat([pos, pos], dim=0)
loss = -torch.log(pos / neg).mean()
return loss
Training is implemented as a regular PyTorch training loop.
High-level, multi-gpu implementation
While working on this project I found the recently added SimCLR module (and also MoCo) in the PyTorch Lightning Bolt implementations. This high level API can be fed with your custom dataset (currently I am doing a POC on this) and trained on a multi-gpu server machine just in a few lines of code:
train_dataset = CustomDataset(..., transforms=SimCLRTrainDataTransform(input_height=512))
model = SimCLR(batch_size=BATCH_SIZE, num_samples=len(train_dataset))
trainer = pl.trainer.Trainer(gpus='0, 1, 2', val_percent_check=0.0,
deterministic=True, distributed_backend='dp')
trainer.fit(
model,
torch.utils.data.DataLoader(train_dataset,
batch_size=BATCH_SIZE,
num_workers=NUM_WORKERS))
It is sometimes amazing how accessible APIs have become.
@Regards, Alex

Alex Olar
Christian, foodie, physicist, tech enthusiast